
En el anterior post te explicamos cómo, utilizando el módulo de R ChoiceModelR, podías llegar a conseguir un fichero (llamado RBetas), el “núcleo duro” de todo el análisis que puedes hacer con los resultados de un conjoint.
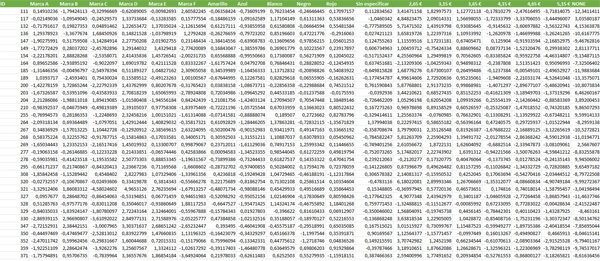
Este fichero RBetas es un csv que tendrás que trabajar un poco antes de ponerte con el análisis. Así es su apariencia original:

En primer lugar, para no tener problemas con posterioridad, si es que trabajas con comas en lugar de puntos como separadores decimales, sustituye todos los puntos del fichero por cualquier carácter no incluido en este fichero. Puedes utilizar, por ejemplo, la arroba.
En segundo lugar, separa las columnas delimitadas por comas. Aquí se explica cómo hacerlo.
En tercer lugar, sustituye todas las arrobas por comas. Ya casi tendrás el fichero RBetas tal y como lo necesitas.
En cuarto lugar, para trabajar más cómodamente, deberías cambiar las etiquetas de las columnas. A1 corresponde al primer atributo que cargaste a ChoiceModelR; A2 al segundo atributo; A3, al tercero (marca, color y precio, según el ejemplo que vamos siguiendo).
El último número de cada cabecera indica el código del nivel, que corresponde también con el que asignaste anteriormente. Así, una vez aplicados estos cambios, deberías haber llegado a un fichero similar a este:
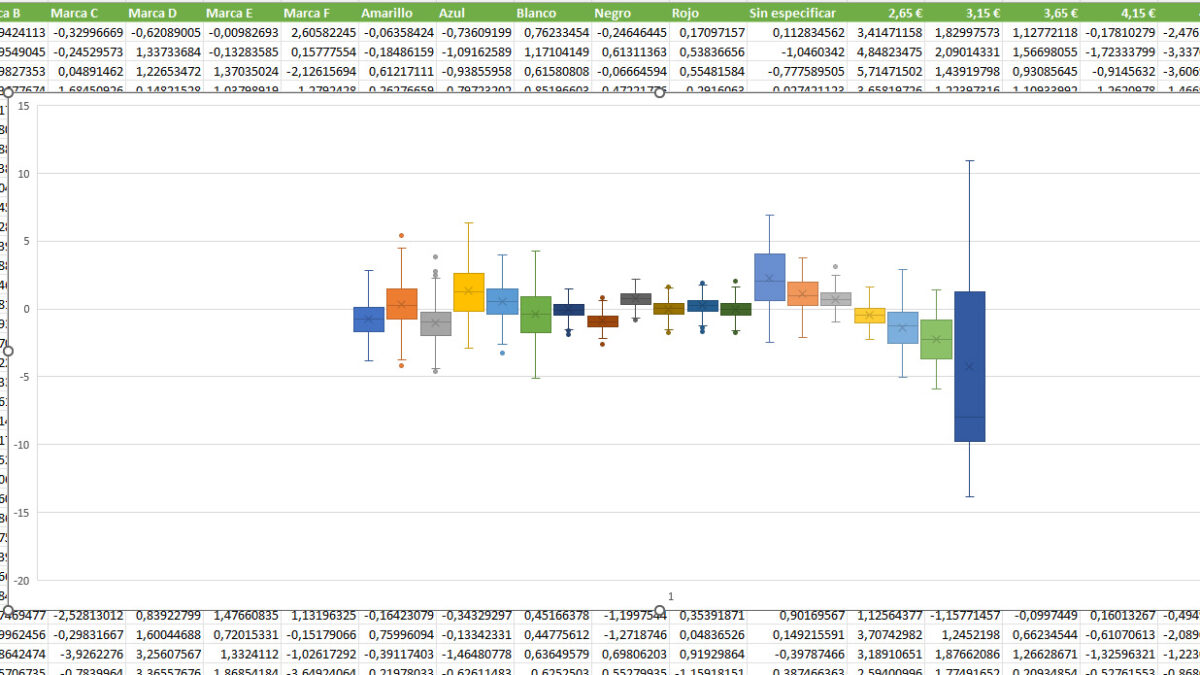
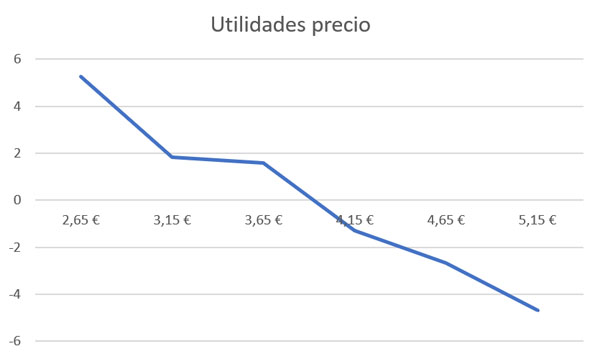
Ahora sí. Ya lo tienes todo listo para empezar con el análisis. Este fichero RBetas te muestra, para cada individuo (reflejado a través de una fila e identificado con la id que cargaste a ChoiceModelR), qué utilidades corresponden a cada uno de los niveles de los atributos. Sin embargo, el análisis individual te aportará datos muy poco fiables. Piensa que, en el experimento del ejemplo, cada encuestado ha visto solo 20 combinaciones de producto distintas ¡de un total de 216 combinaciones posibles!
El análisis hay que hacerlo, pues, en términos agregados. No es mala idea, antes de empezar, hacer un análisis de la dispersión de utilidades de cada nivel (unos cuantos gráficos de caja te servirían para hacerte una idea aproximada). Si hay niveles con una elevada variabilidad, es posible que los datos escondan diferencias entre distintos grupos de consumidores (adolescentes y adultos, por ejemplo), cosa que haría recomendable segmentar los datos para sacar modelos distintos para cada una de estas categorías sociales.
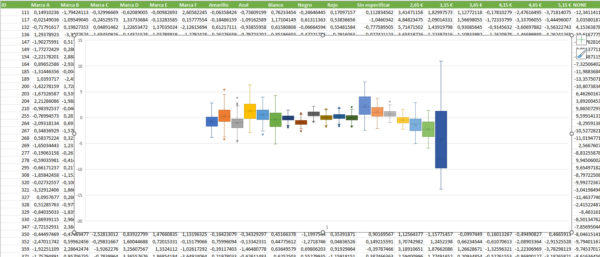
En nuestro ejemplo, se observa una categoría con una elevada variablidad: el “Ninguno de los anteriores”, que diferencia a los realmente interesados en el producto de los que, en muchas ocasiones, preferirían no comprar ningún producto antes que los dos que se le muestran en la pantalla.
A continuación tendrías que sacar las medias de cada uno de los niveles… y obtendrás la utilidad media de cada uno de ellos. ¿Qué podemos hacer con estas utilidades? Te lo explicamos en el siguiente post.

{kind=link}
{kind=link}