
Después de haber introducido brevemente el análisis conjoint, ahora te explicaremos, paso a paso, como analizar sus resultados a través del software libre R.
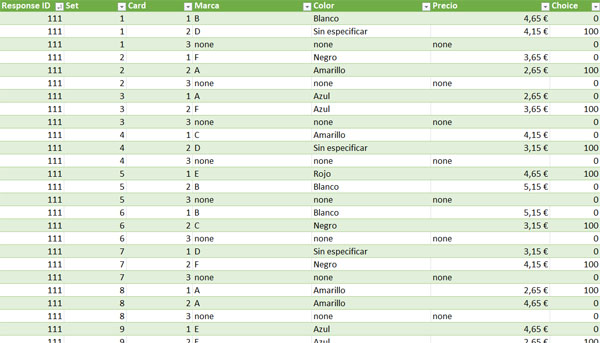
Una vez ya has recogido tus datos, Alchemer nos permite descargar un fichero parecido a este. No pasa nada si tu base de datos tiene un formato distinto; tanto si trabajas con Alchemer como a través de otros métodos vamos a tener que trabajar los datos para poder cargarlos a R. Lo que sí que es imprescindible es que cada línea del Excel se refiera a cada combinación de atributos mostrados en cada pantalla.
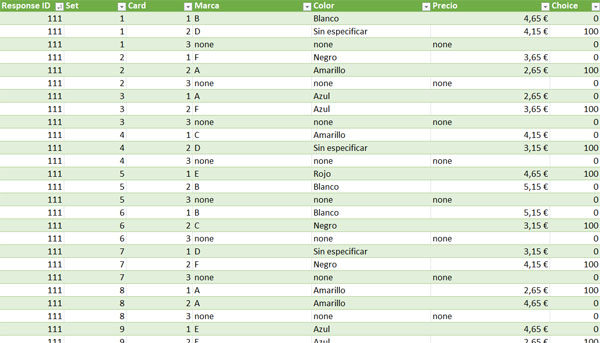
Esta base de datos es el resultante de un ejercicio ficticio en el que cada producto es el resultante de la combinación de tres atributos distintos: marca, color y precio. La columna “ID” es el identificador único del encuestado. La columna “set” indica la pantalla en la que se ha mostrado al encuestado el producto en cuestión (toma valores del 1 al 10, ya que en este ejemplo se muestran 10 pantalladas por encuestado). La columna “card” indica la posición de cada producto en cada set (1, 2 y, para los “Ninguno de los anteriores”, 3). La columna “choice” indica, mediante un 100, qué producto se ha seleccionado en cada set. Las filas que contienen el término “none” se refieren a la opción “Ninguna de las anteriores”.
El siguiente paso es la transformación de este archivo para poder cargarlo a choiceModelR, el módulo de R que emplearemos para calcular los resultados del conjoint. La idea es la siguiente: para cada set, la primera card deberá señalar, en la columna “choice”, cuál de las tres cards se ha seleccionado (1,2 ó, en el caso de “Ninguno de los anteriores”, 3). Para conseguir este resultado, al lado de la columna “choice” puedes aplicar la siguiente función de Excel a la primera fila, y extenderla hasta el final de la tabla:
=SI(H2=100;1;SI(H3=100;2;SI(H4=100;3)))
Con esto conseguirás que todas las primeras filas de cada set reflejen la elección que ha hecho el encuestado.
A todas las cards cuyo valor no sea igual a 1 se les asignará, en la columna “choice”, el valor 0. Y todas las filas correspondientes al “none” deberán ser borradas del archivo.
A continuación, se tienen que transformar los valores categóricos de los niveles de nuestros atributos a códigos numéricos. No es estrictamente necesario, pero dado que choiceModelR lo hará igualmente, mejor tener claro ya de inicio qué códigos numéricos corresponderán a cada uno de los niveles. Y recuerda anotar estas correspondencias.
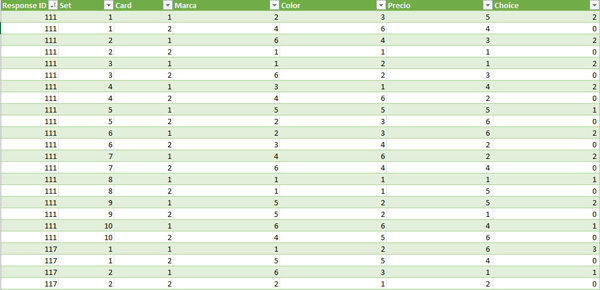
La transformación del anterior fichero según los cambios que se acaban de comentar debería dar como resultado un fichero parecido al de esta imagen. Es muy importante que las filas mantengan el mismo orden: las cards ordenadas siempre de menor a mayor y, los sets, ordenados también de menor a mayor. Finalmente, ordena también de menor a mayor la id del encuestado. Si no lo ordenas así, choiceModelR será incapaz de aplicar el algoritmo MCMC (Markov chain Monte Carlo). Ah, y guarda el fichero en formato csv.
Ya está todo preparado para subir los datos a R y analizar los datos del conjoint. En el siguiente post te explicaremos cómo procesar la información a través del paquete choiceModelR.

{kind=link}
{kind=link}